Surprising Things
It works on apps you didn't build
The assistant is part of the engine, not the app. Open any .melker file and press Alt+H. The AI can describe the UI, read content, and click buttons — even if the app author never thought about AI assistance. It's like having a screen reader that can also operate the controls.
It handles forms end-to-end
"Fill in the registration form with test data" — the model iterates through inputs, selects, checkboxes, and radio buttons in sequence, using a fresh context snapshot after each action. It sees what changed and adapts.
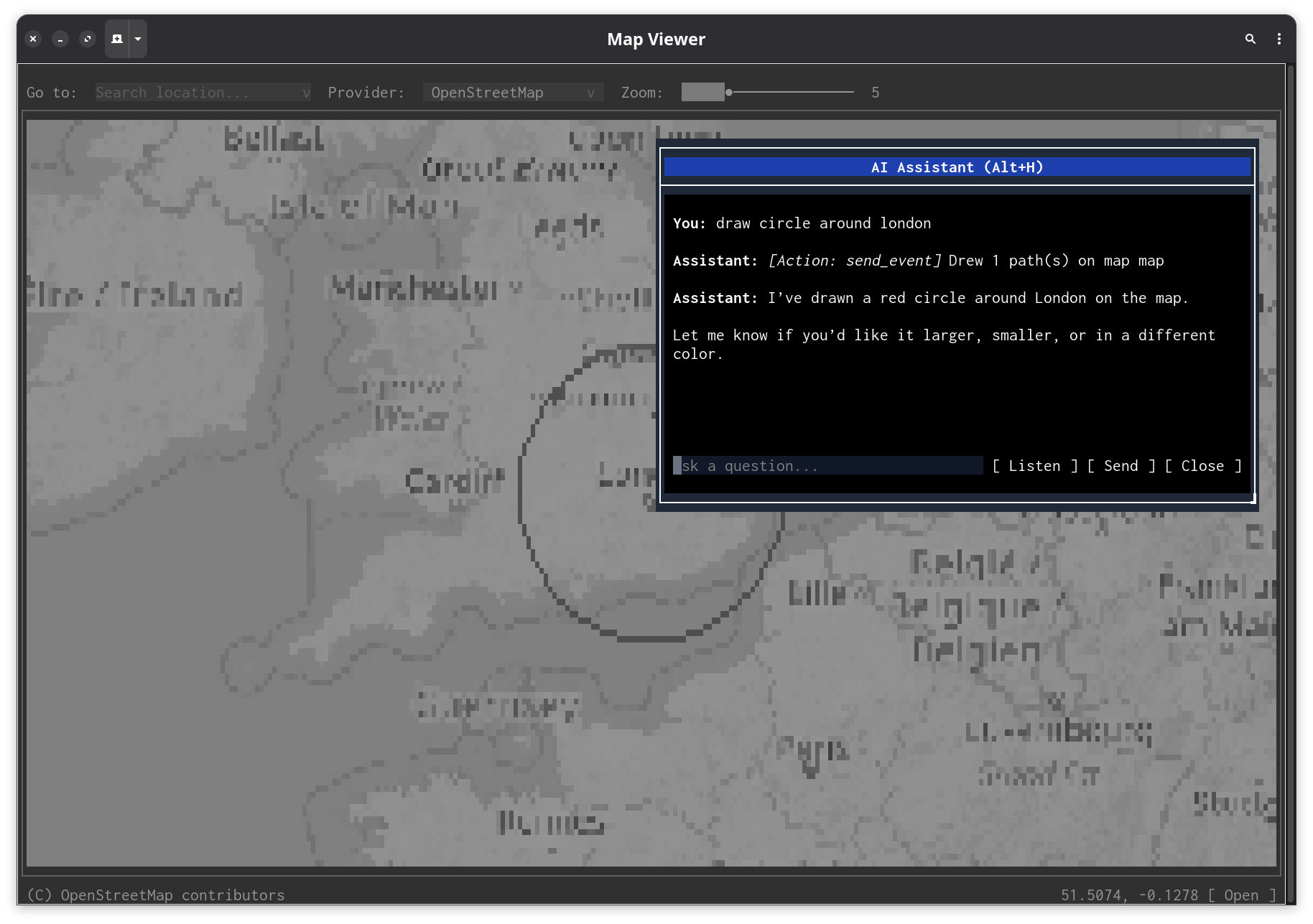
It draws on maps from natural language
"Draw a route from Paris to Berlin" produces SVG path overlays on tile-map components, with the AI choosing appropriate coordinates, stroke colors, and labels. It uses arc commands for circles, Bezier curves for smooth routes, and text elements for labels.
Voice makes terminal apps conversational
A terminal dashboard where you press F7 and say "zoom into the US east coast" or "what's the highest value in the heatmap" turns a display-only interface into something interactive without writing any handler code.
ARIA attributes compose with AI understanding
Standard web accessibility attributes gain a new dimension. aria-description="Shows real-time sensor readings, updates every 5s" doesn't just help screen readers — it tells the AI what the data means. The model can then answer "is the temperature sensor working?" by checking if values are updating.
It can close itself
The model has a close_dialog tool. "Check the current temperature and close" — it reads the value, responds, and dismisses its own dialog. It also has exit_program, which exits the app entirely.